TL;DR 本文使用最小二乘,极大似然,贝叶斯估计方法
当一个分布的均值存在时,我们总是使用样本均值分布
作为真实均值 的估计。本文用不同的思路分析,虽然殊途同归,但希望展示不同统计思想的精华。
点估计性质
样本均值是真实均值的无偏估计。
利用 Cramér-Rao下界(CRLB, Cramér-Rao Lower Bound) 也可以证明在服从NID前提下样本均值也是最小方差无偏估计(MVUE, Minimum Variance Unbiased Estimator)。
estimator 当服从正态分布时候,如果样本中有离群点最好使用中位数?为什么
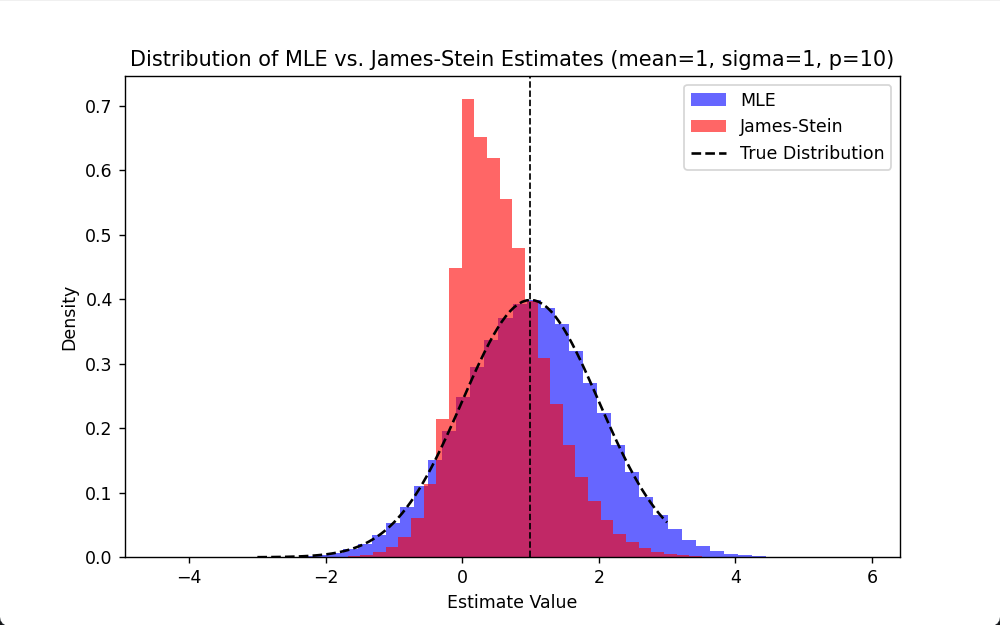
James–Stein estimator降低variance
james-stein通过乘以一个0-1的系数,这个系数来自于总体的信息,使得估计的方差减小。 如何理解?这个系数收缩在p更大,sigma更大,SS更小
最小二乘
使用样本均值作为分布均值的估计可以使得方差和SS(sum of square)最小
样本误差为什么除以n-1
我们一般适用样本均值估计真实均值,这样做的副作用这样有一个副作用使得SS总是小于等于真实SS(等号仅在 取 时候成立), 即倾向于低估方差和。
经过计算方差和的期望为,因此除以n-1才是真实方差的无偏估计。
极大似然法
当 时,有似然函数
使得似然函数最大相当于最小化平方误差
注意到似然函数,这同时使得方差和SS最小。 这说明当error独立同分布服从正态分布时候,最小二乘本质上是极大似然估计。
线性回归
从这个视角看,实际上是寻找一条水平线,拟合这些散点,常用的平方损失。
贝叶斯估计
频率学派认为 是一个定值,而贝叶斯学派认为 是一个分布,并且可以根据经验假定 服从某一先验分布 。 根据贝叶斯公式
类似的,根据观测数据更新先验分布得到后验分布
得到后验分布后,得到 的点估计和区间估计都很容易,常用的得到点估计的方法是取后验分布的期望。