在生物医学统计与临床试验中,我们面临的核心问题往往被简化为:“患者还能活多久?”。直觉上,这似乎是一个标准的回归问题:输入特征 (年龄、基因表达、治疗方案),预测目标 (生存时间)。
然而,如果直接应用线性回归(Linear Regression, OLS),我们将得到系统性的错误结论。生存分析(Survival Analysis)并非是简单的“关于时间的统计学”,而是一套专门用于处理信息不对称与动态风险的数学框架。
核心矛盾:为何 OLS 在时间-事件数据中失效?
线性回归建立在 的假设之上,它要求每一个样本的 都是确定的观测值。但在生存分析中,我们观测到的随机变量并非单纯的时间 ,而是一个二元组 :
其中 是真实的事件发生时间(如死亡), 是删失时间(Censoring Time,如失访或实验结束)。
右删失(Right Censoring)不仅是数据的缺失,更是一种不等式约束:对于删失样本,我们仅知真实时间 。
如果我们强行使用线性回归,将面临无法调和的偏差:
- 丢弃法:若剔除所有删失样本,样本空间将被非随机截断(通常活得长的才会被删失),导致 被严重低估。
- 填充法:若直接令 ,则混淆了“观测结束”与“事件发生”,无法区分治疗带来的生存获益与实验设计的截断效应。
因此,生存分析的第一性原理,是放弃对 的直接拟合,转而构建在不等式约束下的概率密度函数。
非参数估计:Kaplan-Meier 的条件概率积
既然不能直接对时间取均值,我们转向估计生存函数(Survival Function) 。
Kaplan-Meier (KM) 估计量的核心洞见在于:长期生存是瞬间存活的累积结果。 要活过时刻 ,前提是必须活过时刻 ,且在时刻 未发生事件。利用条件概率公式:
这导出了经典的 KM 乘积限公式:
其中:
- :在 时刻发生的死亡人数。
- :在 时刻处于风险集中(At Risk)的总人数。
删失数据的数学贡献
删失样本并没有被丢弃,也没有被视为死亡。它们通过动态调整分母 参与计算。当一个个体在 时,他作为分母的一部分,为“存活率”提供了证据支持;当 后,他从风险集 中移除,不再干扰后续的概率估计。
Cochran-Mantel-Haenszel (CMH) 检验
Log-Rank 实际上是 Cochran-Mantel-Haenszel (CMH) 检验在生存分析中的特例。CMH 的核心用途是:在控制混杂因素(分层)的情况下,检验两个二分类变量的关联性。 例如测试新药是否有效(不考虑随时间的survival rate下降), 只看一年内患者存活率.但是 考虑老年人更容易死亡,需要对年龄进行分层.
差异检验:Log-Rank Test 与列联表本质
当我们得到两条生存曲线时,如何从统计学上判定它们存在显著差异?我们不能简单比较中位生存时间,因为曲线形状可能各异。
Log-Rank 检验(对数秩检验)的名称极具误导性,它本质上是一个分层卡方检验(Stratified Chi-squared Test)。
其推导逻辑如下:
- 离散化:将连续的时间轴离散化为每一个事件发生的瞬间 。
- 构建列联表:在每一个 ,构建一个 表格(组别 事件状态)。
- 零假设 :假设两组的风险分布相同,则组 1 在 的期望死亡人数 应由其在风险集中的占比决定:
- 统计量构造:Log-Rank 统计量 是所有时间点i上“观测值 ”与“期望值 ”差异的加权累积:
常见误区
Log-Rank 的自由度为(组别-1), 与样本量 (N) 无关,也与事件发生次数 (D) 无关。
命名溯源
“Log-Rank” 这一名称源自 Peto & Pike (1966),其数学形式与 Savage Test(基于对数秩的评分)有关。但在应用层面,将其理解为时间加权的 Cochran-Mantel-Haenszel 检验 更为直观且准确。
半参数建模:Cox 比例风险模型
KM 估计和 Log-Rank 检验仅适用于单因素分析。为了量化多个协变量(如年龄、治疗、基因型)对生存的影响,我们需要引入回归模型。这里需要从“概率”视角切换到“风险”视角。
风险函数 (Hazard Function)
风险函数 定义为在时刻 存活的条件下,下一瞬间发生事件的瞬时速率:
Cox 模型的构造
Cox 比例风险模型(Cox Proportional Hazards Model)提出了如下半参数结构:
该公式的精妙之处在于将问题解耦:
- (基准风险):代表随时间变化的自然风险(如衰老)。Cox 模型不假设其服从任何特定分布(Weibull, 指数等),这赋予了模型极大的灵活性(半参数)。
- (部分风险):代表协变量带来的乘法效应。
风险比 (Hazard Ratio, HR)
当我们比较两组样本(如 vs )时,未知的基准风险 在比值中被消去:
HR 的物理意义:它是一个倍率(Rate Ratio)。 意味着在任意时刻,实验组发生事件的速率是对照组的 2 倍。
模型的边界:交叉曲线与 PH 假设
Cox 模型的广泛应用建立在一个极强的假设之上:比例风险假设(Proportional Hazards Assumption, PH)。即 必须是常数,不随时间 变化。
这意味着在双对数坐标系 下,两条生存曲线必须平行。但在临床实践中,这一假设常被打破,最典型的即为**交叉曲线(Crossing Curves)**现象。
案例:手术 vs 保守治疗
- 阶段 A(高风险手术期):手术组面临麻醉、创伤和并发症风险,短期死亡率高于保守组(,即 HR > 1)。
- 阶段 B(恢复期):手术根除了病灶,长期复发率低;保守组病情持续恶化(,即 HR < 1)。
后果: 此时, 实际上是时间的函数 。如果我们强行拟合一个标准的 Cox 模型,算法会输出一个类似 的平均值。这不仅掩盖了真实的生物学效应,更会导致统计推断的失效。
应对策略:
面对交叉曲线,应当:
- 使用 分段 Cox 模型 (Piecewise Cox Model),在不同时间区间分别计算 HR。
- 使用 RMST (Restricted Mean Survival Time) 作为替代评价指标。
Python 实现 (Lifelines lung)
以下代码展示了如何利用 lifelines 库进行完整的生存分析流程。
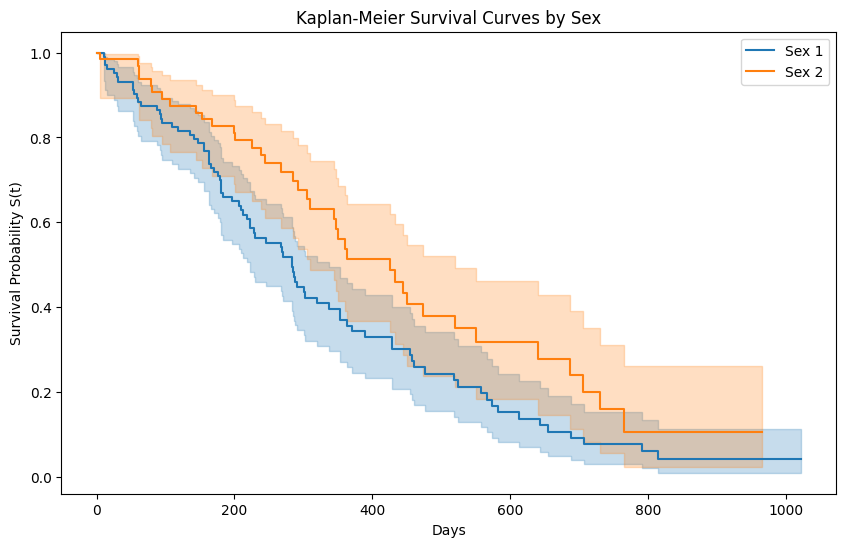
import pandas as pd
import matplotlib.pyplot as plt
from lifelines import KaplanMeierFitter, CoxPHFitter
from lifelines.statistics import logrank_test
from lifelines.datasets import load_lung
# 1. 数据加载与预处理
# event: 1=死亡, 0=删失
df = load_lung()
df = df.dropna()
T = df['time']
E = df['status']
# 2. Kaplan-Meier 估计与可视化
kmf = KaplanMeierFitter()
plt.figure(figsize=(10, 6))
# 按性别分组 (1: Male, 2: Female)
ax = plt.subplot(111)
for name, grouped_df in df.groupby('sex'):
kmf.fit(grouped_df['time'], grouped_df['status'], label=f"Sex {name}")
kmf.plot_survival_function(ax=ax)
plt.title("Kaplan-Meier Survival Curves by Sex")
plt.ylabel("Survival Probability S(t)")
plt.xlabel("Days")
plt.show()
# 3. Log-Rank 检验 (本质:列联表卡方检验)
results = logrank_test(
df[df['sex'] == 1]['time'], df[df['sex'] == 2]['time'],
df[df['sex'] == 1]['status'], df[df['sex'] == 2]['status']
)
print(f"Log-Rank Test p-value: {results.p_value:.4f}")
# 4. Cox 比例风险模型
# 将分类变量转换为虚拟变量,并拟合模型
cph = CoxPHFitter()
cph.fit(df, duration_col='time', event_col='status')
# 输出 HR (exp(coef)) 及其置信区间
cph.print_summary()
# 5. 检验比例风险假设 (PH Assumption)
# 如果 p-value < 0.05,则说明违反 PH 假设(可能存在曲线交叉)
print("Proportional Hazards Assumption Check:")
cph.check_assumptions(df, p_value_threshold=0.05)总结
生存分析并非简单的“存活时间统计”,它是对右删失引起的信息缺失进行数学重构的过程。
- Kaplan-Meier 通过条件概率连乘,解决了“如何利用中途退出者信息”的问题。
- Log-Rank 利用列联表卡方检验,解决了“如何比较整体分布差异”的问题。
- Cox 模型 通过消去基准风险,解决了“多因素影响量化”的问题。
但在应用 Cox 模型输出 HR 时,必须警惕交叉曲线的存在,因为这意味着风险比随时间动态变化,单一的 HR 数值已失去物理意义。