设想我们对比两种质谱预处理方法,目标是验证改进后的方法(Group 1)是否能比经典方法(Group 2)鉴定到更多的 Precursor。我们收集了如下实验数据:
Group1 = [28136, 29054, 28910]
Group2 = [13575, 16308, 16912]仅从数值层面观察,Group 1 的最低值(28136)也远高于 Group 2 的最高值(16912),两组数据在数轴上完全分离。这种差异在生物学上通常被认为具有极强的效应。然而,当我们试图用统计学语言描述这一现象时,问题出现了。由于样本量极小且不确定总体分布,我们采用非参数检验 Mann-Whitney U test。
根据 U 检验的定义,我们计算统计量 U。对于完全分离的两组数据(每组 n=3),计算过程如下:
\begin{align} U_1 &= R_1 - \frac{n_1(n_1+1)}{2} = (4+5+6) - \frac{3 \times 4}{2} = 15 - 6 = 9 \\ U_2 &= R_2 - \frac{n_2(n_2+1)}{2} = (1+2+3) - \frac{3 \times 4}{2} = 6 - 6 = 0 \\ U &= \min(U_1, U_2) = 0 \end{align}
当 且 时,查表可得双侧 P 值为 0.1。这是一个大于 0.05 的数值,意味着在统计学标准下,我们无法拒绝零假设。即使我们将 Group 1 的数值全部乘以 10,拉大差异,P 值依然为 0.1。
NOTE
有时候还会遇到另一种情况,我们发现pvalue极小,但是group1,2之间差异非常小, 这时可能没有继续深入研究的意义.
统计显著性只是一部分?
P 值(Probability value)回答的问题是:如果两组之间实际上没有差异(零假设成立),那么我们在随机抽样中观测到当前数据或更极端数据的概率是多少?它是一个关于“惊奇程度”的度量,而非“差异大小”的度量。
在上述案例中,P 值之所以无法下降,是因为在仅有 3 个样本的情况下,即使数据完全分离,这种排列组合出现的概率本身就不够稀缺。P 值高度依赖于样本量。我们可以通过检验统计量的通用结构来理解这一点:
为了更直观地看到样本量 的作用,我们引入 Mann-Whitney U 检验在大样本下的正态近似公式(Z-score)。虽然小样本下直接查表,但该公式揭示了其内在逻辑:
其中均值 和标准差 完全由样本量决定:
\begin{align} m_U &= \frac{n_1 n_2}{2} \\ \sigma_U &= \sqrt{\frac{n_1 n_2 (n_1 + n_2 + 1)}{12}} \end{align}
观察分母 。随着样本量 的增加,分母虽然增大,但分子中的 值通常以 的速度增长(在效应存在时)。这导致 值随着样本量增加而迅速增大,从而使 P 值趋向于 0。
样本量的杠杆作用
P 值的计算不仅仅取决于数据的差异程度(效应量),更取决于数据的规模(样本量)。大样本量能提供更精确的估算,缩小置信区间。
这意味着,只要样本量足够大,微不足道的生物学差异也能产生显著的 P 值;反之,如本例所示,巨大的生物学差异在小样本下也可能无法通过显著性检验。
效应量:如何度量差异的物理强度?
如果 P 值负责回答“差异是否存在”,那么效应量(Effect Size)则负责回答“差异有多大”。效应量是一个标准化的指标,旨在剔除样本量对统计结果的干扰,直接反映变量关系的强度。
Cohen d
对于常见的两组比较,我们需要根据数据分布特征选择合适的效应量指标:
正态分布数据的均值差异(Cohen’s d):
这是最直观的标准化差异,它衡量实验组与对照组的均值差了多少个标准差。
cliff’s delta
非正态分布数据的秩次差异(Cliff’s delta):
当数据不满足正态分布时,基于均值的度量可能失效。Cliff’s delta 利用优势概率来定义差异,即从两组中各随机抽取一个样本, 的概率减去 的概率。
二分类模型的区分能力(AUC / CLES):
在机器学习或临床诊断中,我们常问:如果我从实验组随机抽一个人,从控制组随机抽一个人,实验组得分高于控制组的概率是多少?这被称为通用语言效应量(Common Language Effect Size),在数值上等同于 ROC 曲线下的面积(AUC)。
回到开头的质谱案例,由于两组数据完全分离(Group 1 的所有值均大于 Group 2),此时:
Cliff’s delta = 1.0
AUC = 1.0
Cohen’s d ≈ 9.0
这些指标极其强烈地提示了生物学差异的存在,完全独立于 P 值 = 0.1 的统计推断。
效应量的大小边界是如何定义的?
计算出效应量后,我们面临下一个问题:多大的效应量才算“大”?常见的做法是参考 Cohen 在 1988 年提出的通用基准。
| 效应量类型 | 小效应 (Small) | 中效应 (Medium) | 大效应 (Large) |
|---|---|---|---|
| Cohen’s d | 0.2 | 0.5 | 0.8 |
| Pearson’s r | 0.1 | 0.3 | 0.5 |
| AUC (CLES) | 0.56 | 0.64 | 0.71 |
| Eta-squared | 0.01 | 0.06 | 0.14 |
这些通用基准本质上是基于经验的,类似于 P 值 0.05 的阈值。在复杂的生物学研究中,直接套用心理学或社会学导出的 Cohen 标准往往不准确。
NOTE
例如,在全基因组关联分析(GWAS)中,极微小的效应量(OR 1.05)可能因其明确的机制验证而被视为重要;而在临床药物试验中,均值差异 0.8 可能仍不足以证明药效优于现有疗法。
相对确定法:基于元分析分布的定义
更科学的阈值确定方法应当是“相对”的。我们应当利用该领域的历史数据或元分析(Meta-analysis)构建效应量的经验分布。
我们不再问“0.8 是大还是小”,而是问“在同类蛋白质组学定量实验中,0.8 处于什么样的分位点”。如果该领域 90% 的实验效应量都小于 0.5,那么 0.8 无疑是巨大的。
这种基于先验分布的思维,将效应量的判断从“绝对数值”转化为“相对稀缺性”,更符合贝叶斯推断的逻辑,也能更准确地指导后续实验的成本与价值评估。
样本量在不同effect size下对于pvalue的影响
在上述质谱实验中,实际上遇到了 II 型错误(Type II Error,即 ):事实上存在差异,但统计检验未能检测出来。
为了避免重蹈覆辙,我们需要引入统计功效(Statistical Power),定义为 。它代表了在效应量真实存在时,我们正确拒绝零假设的概率。通常,科学界将功效设定为 0.8,意味着我们希望有 80% 的把握捕捉到真实的生物学差异。
实验设计实际上是一个四元平衡方程,只要确定其中三个,就能解出第四个:
- 显著性水平 ():通常固定为 0.05。
- 统计功效 (Power):通常固定为 0.8。
- 效应量 (Effect Size):基于预实验(如我们的 n=3 数据)或文献估算。
- 样本量 (Sample Size):待求变量。
模拟 P 值的指数级衰减
为了直观理解样本量如何将被压抑的效应量“释放”为显著的 P 值,我们可以构建一个简单的仿真。假设我们固定两组数据的均值差异(即固定效应量),观察随着样本量 从 3 增加到 50,P 值是如何变化的。
这里我们使用 Python 进行模拟,模拟两种场景:
- 大效应场景:Cohen’s d = 2.0(类似我们要验证的改进方法)。
- 中效应场景:Cohen’s d = 0.5(常规的生物学差异)。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
def simulate_p_value_decay(effect_size, max_n=50, n_simulations=500):
"""
模拟固定效应量下,P值随样本量增加的衰减趋势
"""
n_values = range(3, max_n + 1)
avg_p_values = []
# 设定组1的基准参数
mu1, sigma = 0, 1
# 根据效应量推算组2的均值 (Cohen's d = (mu2 - mu1) / sigma)
mu2 = mu1 + effect_size * sigma
for n in n_values:
p_list = []
for _ in range(n_simulations):
# 生成模拟数据
group1 = np.random.normal(mu1, sigma, n)
group2 = np.random.normal(mu2, sigma, n)
# 执行t检验
_, p = stats.ttest_ind(group1, group2)
p_list.append(p)
# 记录该样本量下的平均P值
avg_p_values.append(np.mean(p_list))
return n_values, avg_p_values
# 运行模拟
n_axis, p_large = simulate_p_value_decay(effect_size=2.0) # 大效应
_, p_medium = simulate_p_value_decay(effect_size=0.5) # 中效应
plt.figure(figsize=(10, 6))
plt.plot(n_axis, p_large, label="Large Effect (d=2.0)", color="#e74c3c")
plt.plot(n_axis, p_medium, label="Medium Effect (d=0.5)", color="#3498db")
plt.axhline(0.05, color='gray', linestyle='--', label="Significance Threshold (0.05)")
plt.xlabel("Sample Size (n)")
plt.ylabel("Average P-value")
plt.title("P-value Decay: Effect Size vs Sample Size")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()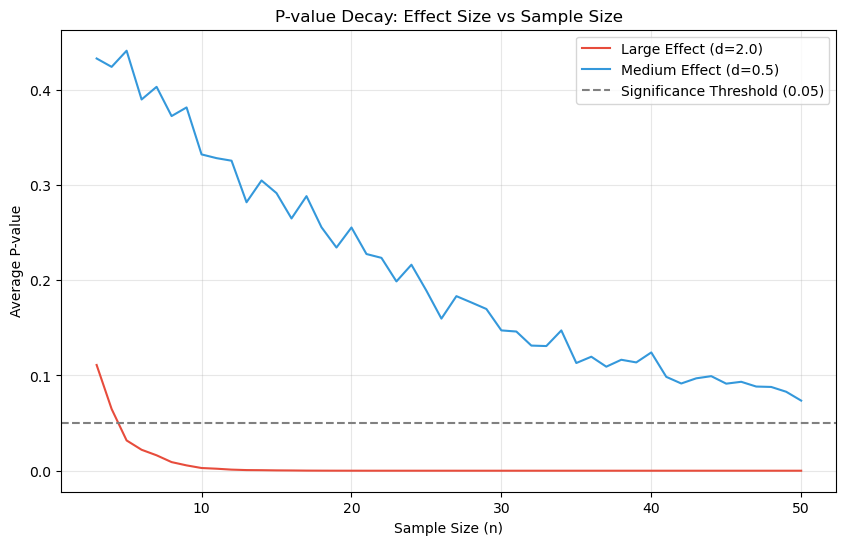
运行上述代码后,我们会得到两条不同的 P 值衰减曲线
-
大效应的“断崖式”突破: 对于 Cohen’s d = 2.0 的情况(红色曲线),P 值在样本量 或 时就会迅速击穿 0.05 的阈值。这意味着,对于这种极强的改进方法,我们只需要极少的额外样本(从 3 个增加到 5 个)就能获得统计学上的确认。之前的 失败,仅仅是因为我们要么正好处于临界点的左侧,要么使用了检验力较弱的非参数检验。
-
中效应的“漫长”衰减: 对于 Cohen’s d = 0.5 的情况(蓝色曲线),P 值下降非常缓慢。即使样本量增加到 20 或 30,平均 P 值可能仍在 0.05 附近徘徊。这解释了为什么许多生物学实验(通常效应量有限)在样本不足时总是得到“模棱两可”的结果。
边际效应递减
注意曲线的形状。在突破 0.05 之后,继续增加样本量,P 值会无限趋近于 0,但这时的“科学价值”增量是递减的。从 增加到 并不能改变结论的性质(都是显著),却极大地增加了实验成本。Power Analysis 的核心目的,就是找到那个刚好跨过阈值的“甜点(Sweet Spot)”。
总结与展望
在科学研究中,我们必须区分“统计上的惊讶”(Significant P-value)与“实际的显著”(Substantial Effect Size)。
P 值是样本量的函数,它告诉我们在当前样本规模下,结论的可靠程度。效应量是生物学事实的投影,它告诉我们该发现的实际强度。
参考
https://onlinelibrary.wiley.com/doi/10.1111/j.1469-185X.2007.00027.x